Пасхалия в sed.
Получение даты празднования Пасхи с использованием александрийской пасхалии.
Содержание:
- Введение
- Описание вспомогательного языка
- Расчёт даты
- Тестирование
- Возможные улучшения
- Ссылки
Введение
Во время поста перед Пасхой решил написать сценарий (скрипт) computus.sed [1] для хорошо известного поточного текстового редатора sed, расчитывающий дату
празднования (в данном случае православной) Пасхи.
Пример использования скрипта computus.sed:
echo 2020 | ./computus.sed
# April, 19
Исходное определение даты праздования Пасхи выглядит не очень сложно [2,3]. Согласно ему, день празднования Пасхи приходится на первое воскресение после первого полнолуния, наступившего не ранее весеннего равноденствия. Программный расчёт этой даты подразумевает моделирование движения земли и луны, либо, что проще для реализации, аппроксимацию полу-эмпирическими формулами.
Проблема только усложняется тем, что эта дата — т.н. астрономическая Пасха — из-за принятого в церкви алгоритма расчета указанных астрономических событий (полнолуние, равноденствие), витиеватой истории календарных реформ и ряда дополнительных специальных соглашений/оговорок, сильно отличается от фактических дат (тоже сильно различающихся между собой) празднования Пасхи в различных церквях/религиях.
Это обстоятельство вместе с [почти] полным отсутствием поддержки арифметики в sed сделало написание этого скрипта несколько нетривиальной задачей (хотя периодичность результатов пасхалии, а именно повторение дат с периодом в 532 года, в принципе позволяет обойтись и радужными таблицами, что не так интересно).
Поэтому сначала был написан простой интерпретатор для постфиксного (обратная польская нотация, далее кратко rpn) языка, использующего стек/«магазин» (но поддерживающего именованные переменные).
Описание вспомогательного языка
Весь rpn-скрипт состоит из последовательности «слов», разделенных пробелами. Слова могут быть числами или командами. Слова перечисляются и обрабатываются (выполняются) «слева-направо» (т.е. с первого до последнего).
Целое положительное число в десятичной записи преобразуется в унарную запись и кладётся на вершину стека.
Команды:
- Сравнение:
eq. Удаляет из стека два верхних элемента, сравнивает их и кладет на вершину стека единицу если аргументы равны, и ноль – в противном случае. - Работа с переменными:
set,get. Синтаксис:set_<variable>иget_<variable>, где<variable>– имя изменяемой или, соответственно, читаемой переменной (без угловых скобок). При записи, с вершины стека удаляется значение и записывается в указанную именованную переменную. При чтении значение из переменной добавляется на стек. - Аддитивные арифметические операции:
plus,minus. Эти операции удаляют два значения-аргументы со стека, складывают или находят их разность (причем вычитать можно только из большего меньшее), а результат кладут на стек. - Мультипликативные операции:
div,mod. Эти операции тоже берут со стека два значения и кладут результат обратно на вершину. Операцияdivпроизводит целочисленное деление,mod– находит остаток от деления. - Условный оператор:
if ... then. При выполнении командыifпроверяется вершина стека и если на вершине лежит ноль, то блок междуifи ближайшим, расположенным правее, словомthenпропускается, иначе блок выполняется (N.B., вложенность не поддерживается).
На данный момент все арифметические операции производятся в унарной системе счисления. К примеру, для проверки високосности 2020 года требуется среди прочего найти остаток от деления на 4, а для этого требуется записать 2020 единиц в буфер редактирования и начать последовательно удалять по 4 единицы за раз, пока не останется менее четырех единиц, что и будет требуемым остатком. Да, это очень медленно, но обеспечивает особую простоту кода.
Аналогично, деление описывается следующим псевдокодом:
swap_stack();
a=pop_stack();
b=pop_stack();
c=0;
while(a>b)
{
a-=b;
c++
}
push_stack(c);
Эта логика в computus.sed реализуется следующим фрагментом (обратите внимание, что некоторые
строки прокомментированы соответствующими строками из вышеприведенного псевдокода):
/^div/ {
s/\n(1*)\n(1*)@/\n\2\n\1@/ # swap_stack();
s/@/\n@/ # c=0;
:div_iterations
/\n(1*)\n1*\1\n/! bnot_matched
s/\n(1*)(\n1*)\1(\n1*@)/\n\1\2\3/ # a-=b.
s/\n(1*)@/\n1\1@/ # c++.
bdiv_iterations
:not_matched
s/\n1*\n1*(\n1*@)/\1/
}
В основе этого фрагмента лежит соответствующая строке a-=b sed-инструкция
s/\n(1*)(\n1*)\1(\n1*@)/\n\1\2\3/. Здесь работа ведется
с двумя унарными числами, разделенными переводом строки (\n). Мы ищем (с
помощью обратной ссылки или «back-reference») первое число «внутри» [записи] второго:
(1*)(\n1*)\1, и при удачном сопоставлении заменяем совпавший шаблон на строку \1\2, включающую
ссылки на первые две группы в круглых скобках из шаблона, — т.е. (1*) и (\n1*), — и
игнорирующую «хвостовую» часть второго числа, находящуюся, как вы можете видеть, за пределами
скобок: (\n1*)\1.
Эта процедура, по-сути, удаляет первое число из второго, т.е., говоря другими словами, вычитает первое
число из второго, чем, собственно, и достигается требуемый эффект от операции a-=b (да, порядок
следования «перепутан» из-за стека; за это отвечает строка swap_stack() из пседвокода, меняющая
два числа на вершине стека местами).
В подробном разборе всего кода, естественно, нет особого смысла — ничто не заменит чтения самого
computus.sed.
Расчёт даты
В [2] приведен следующий алгоритм для расчета даты православной Пасхи (здесь
добавлена частичная коррекция даты для поддержки григорианского календаря или т.н. нового
стиля):
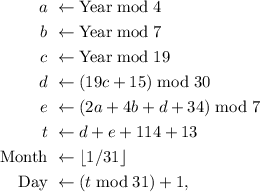
где переменные
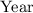 ,
, 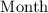 и
и 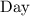 означают текущие год, месяц и
день, соответственно.
означают текущие год, месяц и
день, соответственно.
Для получения дат по григорианскому календарю я просто добавил слагаемое 13 в присваивание
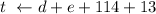 . Т.е. в таком виде этот код не будет правильно работать для дат до 1 февраля
1918 года. Теоретически, это не сложно исправить (однако, см. замечание ниже, в разделе
«Тестирование»).
. Т.е. в таком виде этот код не будет правильно работать для дат до 1 февраля
1918 года. Теоретически, это не сложно исправить (однако, см. замечание ниже, в разделе
«Тестирование»).
Дословная трансляция вышеприведенных формул на уже описанный в предыдущем разделе проблемно-ориентированный миниязык может быть такой:
set_year get_year 4 mod set_a
get_year 7 mod set_b
get_year 19 mod set_c
19 get_c mul 15 plus 30 mod set_b
2 get_a mul 4 get_b mul plus 34 plus get_d minus 7 mod set_e
get_d get_e plus 114 plus 13 plus set_t
get_t 31 div set_mont
get_t 31 mod 1 plus set_day
Несмотря на учёт перехода на «новый стиль», здесь всё ещё остается проблема с датой Пасхи, приходящейся на май (исходные формулы вообще не могут давать майских дней). Ad-hoc коррекция для таких дат может выглядеть следующим образом:
get_month 5 eq if get_day 1 plus set_day then
get_mont 4 eq if get_day 31 eq if
5 set_month 1 set_day then then
Это соответствует такому C-образному псевдокоду:
if(month==5)
day++
else if(month==4)
if(day==31)
{
month=5
day=1
}
В конце rpn-скрипта мы просто кладем готовые месяц и день на стек для дальнейшей печати (с
преобразованием номера месяца в строку):
get_month get_day
Тестирование
В репозитории можно найти файл-список test-easter-dates.txt с некоторыми проверочными датами и
скрипт dictionary-test.sh для автоматического тестирования с их использованием. Спешу лишь
предупредить о достаточно большом времени, требуемом для завершения работы скрипта даже для
относительно небольшого диапазона дат, включенных в указанный файл (1994–2034 гг.)
Кроме этого был написан на perl простой скрипт-обёртка computus.pl, принимающий год в качестве
аргумента командной строки, расчитывающий дату празднования Пасхи с помощью модуля Dates::Easter
[4] и возвращающий её в том же формате, что и computus.sed. Он может
использоваться для сравнительного тестирования моего скрипта, а с целью упрощения этой процедуры
для диапазонов дат, можно воспользоваться сценарием оболочки range-test.sh.
Пример:
./computus.pl 2020
# April, 19
./range-test.sh 2018 2021
# 4 tests performed, 4 tests passed, 0 tests failed.
Для меня пока остаётся открытым вопрос о работоспособности скрипта computus.sed для
всего XXI века, а также для дат, предшествовавших реформе 1918 года, вплоть до времен разработки
и начала применения пасхалии (хотя конкретно этот алгоритм, по-видимому, не будет работать для
времени более раннего чем 1583 год, что связано с введением григорианского календаря именно в 1582
году; это требует уточнения). К слову, computus.pl согласуется с моим для текущего века, но
расходится с моим на один день для века XIX, что, возможно, связано с вопросом о новом
стиле, хотя в начала XX века, скрипты дают одинаковые даты, а это уже свидетельствует о
наличии в perl-модуле Dates::Easter той же или похожей недоработки, что и в моём случае.
Вообще, в календарных расчетах должно учитываться (и, по всей видимости, в Dates::Easter это
учитывается), что разница между юлианским и григорианским
календарями зависит от конкретного века (и увеличивается на 3 за 4 века).
Эту зависимость можно проиллюстрировать следующей таблицей-примером:
| Века | Коррекция (сутки) |
|---|---|
| XIV | 8 |
| XV | 9 |
| XVI–XVII | 10 |
| XVIII | 11 |
| XIX | 12 |
| XX–XXI | 13 |
| XXII | 14 |
Также должна учитываться и конкретная дата внутри века, причем не самым систематичным образом. E.g., коррекция в 10 дней действует с 5 октября 1582 года по 28 февраля 1700 года, а коррекция в 11 дней — с 1 марта 1700 года по 28 февраля 1800 года. (При этом, я слышал, что православная церковь просто использует фиксированную разницу в 13 дней всегда; это утверждение требует дополнительной проверки)
В любом случае, несмотря на то, что Dates::Easter соблюдает вековое варьирование разницы между
календарями, мой скрипт, или по крайней мере его текущая версия, использует именно фиксированную
поправку +13, впрочем, исключительно ради простоты реализации. Посмотрим, что будет в XXII веке с его
четырнадцатидневной коррекцией. :)
Возможные улучшения
За счёт использования стекового dsl-языка представляется относительно несложной задача адаптации настоящего скрипта к другим вариантам Пасхи, включая католическую и еврейскую. Поддержку астрономической Пасхи прямым моделированием планетарного движения на sed реализовать сложнее, но можно подобрать, как уже было отмечено, приближенные формулы. Например, что несколько неожиданно, ядро расчета еврейской Пасхи, кажется, достаточно точно соответствует астрономической дате (это, однако, нивелируется по меньшей мере соглашениями о невозможности её празднования в определенные дни недели).
Другим очевидным (но не приоритетным) направлением для улучшения обсуждаемого sed-сценария
является ускорение его работы, например переходом к десятичной или хотя-бы двоичной системе
счисления. В постфиксном калькуляторе dc.sed [5], написанном Greg Ubben, почти
вся необходимая арифметика уже реализована (и работает с огромной скоростью, в отличии от моей
унарной реализации «счётных палочек»).
Наконец, было бы неплохо исправить описанные в предыдущих разделах ошибки с расчётом дат Пасхи в веке XIX и далее в глубь веков. В противоположном направлении по оси времени тоже есть определенные тонкости, вроде необходимости учёта разницы между юлианским и новоюлианским календарями после 2800 года. Дополнительный разбор пасхалии и календарных несоответствий может быть найден в [6].
Ссылки
- 1. https://github.com/Circiter/computus-in-sed
- 2. Meeus J. Astronomical Algorithms. 1991
- 3. http://ru.wikipedia.org/wiki/пасхалия
- 4. http://search.cpan.org/dist/Date-Easter
- 5. http://sed.sourceforge.net/grabbag/scripts/dc.sed
- 6. Календарный вопрос: Сборник статей / под ред. Чхартишвили А. 2000